จะทำงานกับข้อมูลหรือคำสั่งที่เป็นรหัส ไบนารี
ข้อมูลหรือคำสั่งแต่ละชุดประกอบด้วยรหัสไปนารีหลายๆบิต อาจเป็น 8,
16 หรือ 32 บิต เรียงเข้ากัน
เรียกว่า 1 เวิร์ด ในโปรเซสเซอร์ เวิร์ด 1 เวิร์ดจะใช้เป็นรหัสแทนสิ่งต่อไปนี้คือ เลขหนึ่งจำนวน
ตำแหน่งในหน่วยความจำ อักษรหนึ่งตัว สัญลักษณ์หนึ่งตัวและแทนคำสั่งการทำงาน
8.1 รหัสที่ใช้แทนอักขระ
1)
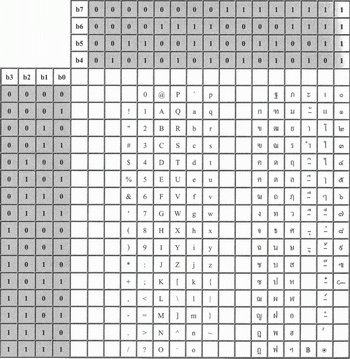
รหัสแอสกี
รหัสแอสกี (ASCII) เป็นเป็นรหัสที่กำหนดขึ้นโดยหน่วยงานกำหนดมาตรฐานของสหรัฐอเมริกา ย่อมาจาก American Standard Code for Information Interchange เป็นรหัส 8 บิต ใช้แทนสัญลักษณ์ต่าง ๆ ได้256 ตัว นิยม ใช้กันแพร่หลายกับระบบคอมพิวเตอร์ทั่วไปและระบบสื่อสารข้อมูล
รหัสแอสกี (ASCII) เป็นเป็นรหัสที่กำหนดขึ้นโดยหน่วยงานกำหนดมาตรฐานของสหรัฐอเมริกา ย่อมาจาก American Standard Code for Information Interchange เป็นรหัส 8 บิต ใช้แทนสัญลักษณ์ต่าง ๆ ได้256 ตัว นิยม ใช้กันแพร่หลายกับระบบคอมพิวเตอร์ทั่วไปและระบบสื่อสารข้อมูล
จากหลักการของระบบเลขฐานสอง
แต่ละบิตสามารแทนค่าได้ 2 แบบ คือ เลข 0 หรือเลข 1 ถ้าเราเขียนเลขฐานสอง เรียงกัน 2 บิต ในการแทนอักขระ เราจะมีรูปแบบในการแทนอักขระได้ 2 หรือ 4 รุปแบบคือ 00 ,01 ,10 ,11ดังนั้นในการใช้รหัสแอสกีซึ่งมี 8 บิต
ในการแทนอักขระแล้ว เราจะมีรูปแบบที่ใช้แทนถึง 28 หรือ 256 รูปแบบ ซึ่งเมื่อใช้แทนตัวอักษรภาษาอังกฤษแล้ว ยังมีเหลืออยู่
สำนักงานมาตรฐานผลิตภัณฑ์อุตสาหกรรม หรือ
สมอ.จึงได้กำหนดรหัสภาษาไทยเพิ่มลงไปเพื่อให้ใช้งานร่วมกัน
2) รหัสเอ็บซีดิก
รหัสเอ็บซีดิก (EBCDIC) เป็นคำย่อมาจาก Extended Binary Coded Decimal Interchange Codeพัฒนาและใช้งาน โดยบริษัทไอบีเอ็ม เครื่องคอมพิวเตอร์เมนเฟรมของไอบีเอ็มยังคงใช้รหัสนี้ การกำหนดรหัสจะใช้ 8 บิต หรือ 1 ไบต์ ต่อหนึ่งอักขระ เหมือนกับรหัสแอสกี แต่รูปแบบของรหัสที่กำหนดจะแตกต่างกัน
รหัสเอ็บซีดิก (EBCDIC) เป็นคำย่อมาจาก Extended Binary Coded Decimal Interchange Codeพัฒนาและใช้งาน โดยบริษัทไอบีเอ็ม เครื่องคอมพิวเตอร์เมนเฟรมของไอบีเอ็มยังคงใช้รหัสนี้ การกำหนดรหัสจะใช้ 8 บิต หรือ 1 ไบต์ ต่อหนึ่งอักขระ เหมือนกับรหัสแอสกี แต่รูปแบบของรหัสที่กำหนดจะแตกต่างกัน
โครงสร้างรหัสเอ็บซีดิก มีดังนี้
บิตที่ รหัส ประเภทของตัวอักขระ
0 - 1 01 สัญลักษณ์ต่าง ๆ
10 ตัวหนังสือภาษาอังกฤษแบบพิมพ์ตัวเล็ก
11 ตัวหนังสือภาษาอังกฤษแบบพิมพ์ตัวใหญ่และตัวเลข
2 - 3 00 A - I
01 J - R
10 S - Z
11 ตัวเลข
4 - 7 รหัสแทนอักขระแต่ละตัวในกลุ่ม
3) รหัสยูนิโค้ด
รหัสยูนิโค้ด (Unicode) เป็นรหัสที่สร้างขึ้นมาในระยะหลังที่มีการสร้างแบบตัวอักษรของภาษาต่าง
ๆ รหัสยูนิโค้ด เป็นรหัสที่ต่างจาก 2 ชนิด
ที่ได้กล่าวมา คือใช้เลขฐานสอง 16 บิต
ในการแทนตัวอักษร เนื่องจากที่มาของการคิดค้นรหัสชนิดนี้ คือ เมื่อมีการใช้งานคอมพิวเตอร์ในหลายประเทศและมีการสร้างแบบตัวอักษร
(font) ของภาษาต่าง ๆ ทั่วโลกในบางภาษา เช่น ภาษาจีน
และภาษาญี่ปุ่น เป็นภาษาที่เรียกว่าภาษารูปภาพ ซึ่งมีตัวอักษรเป็นหมื่นตัว
หากใช้รหัสที่เป็นเลขฐานสอง 8 บิต
เราสามารถแทนรูปแบบตัวอักษรได้เพียง 256 รูปแบบซึ่งไม่สามารถแทนตัวอักษรได้ครบ
จึงสร้างรหัสใหม่ขึ้นมาที่สามารถ แทนตัวอักขระได้ถึง 65,536 ตัว
ซึ่งมากพอและสามารถแทนสัญลักษณ์กราฟิกและสัญลักษณ์ทางคณิตศาสตร์ได้อีกด้วย
8.2 รูปแบบคำสั่ง
ไมโครโปรเซสเซอร์ไม่ว่าจะผลิตจากบริษัทไหนก็แล้วแต่
จะมีชุดคำสั่งประจำไมโครโปรเซสเซอร์เบอร์นั้น
พื้นฐานคือคำสั่งจะอยู่ในลักษณะไบนารี
คำสั่งหนึ่งคำสั่งอาจประกอบด้วยไบต์เดียวหรือสองไบต์ สามไบต์ สี่ไบต์
ก็ได้แล้วแต่กรณี ไบต์แรกของคำสั่งเรียกว่าออปโค้ด ไบต์ส่วนที่เหลือเรียกว่า
โอเปอร์แรนด์
องค์ประกอบของคำสั่งภาษาเครื่อง
ภายในเครื่องคอมพิวเตอร์
คำสั่งแต่ละคำสั่งจะอยู่ในรูปของกลุ่มบิต
คำสั่งจะถูกแบ่งออกเป็นเขตข้อมูลหลายส่วนซึ่งใช้แสดงแทนองค์ประกอบแต่ละส่วน
ชุดคำสั่งส่วนใหญ่ใช้รูปแบบคำสั่งมากกว่าหนึ่งแบบเสมอ ในระหว่างทำการประมวลผล
คำสั่งจะถูกอ่านเข้าไปในรีจิสเตอร์คำสั่ง ที่อยู่ภายในซีพียู
ซีพียูจะต้องสามารถดึงข้อมูลแต่ละเขตข้อมูลในรีจิสเตอร์คำสั่งไปใช้ได้อย่างถูกต้องจึงจะสามารถประมวลผลคำสั่งนั้นได้อย่างถูกต้อง
ชนิดของคำสั่ง
คำสั่งภาษาระดับสูง เช่น ปาสคาล หรือ
ฟอร์แทน ตัวอย่างเช่น X = X+Y ประโยคนี้บอกให้คอมพิวเตอร์ นำค่าตัวแปร Y บวกกับค่าตัวแปร X แล้วเก็บผลลัพธ์ไว้ที่ X สมมติว่าให้ใช้ชุดคำสั่งที่ง่ายต่อการทำความเข้าใจแล้ว
ประโยคดังกล่าวจะถูกแปลคำสั่ง ดังนี้
1. อ่านข้อมูลที่เก็บอยู่ที่ตำแหน่ง 513 เข้ามาไว้ในรีจิสเตอร์
2. นำค่าที่เก็บอยู่ใน 514 มาบวกเข้ากับรีจิสเตอร์
3. นำผลลัพธ์ในรีจิสเตอร์ไปบันทึกไว้ที่ตำแหน่ง 513
จากตัวอย่างที่แสดงนี้
นำไปสู่การพิจารณาชนิดของคำสั่งที่จะต้องมีอยู่ในเครื่องคอมพิวเตอร์อเนกประสงค์ทั่วไป
คอมพิวเตอร์ควรมีชุดคำสั่งที่ช่วยให้ผู้ใช้สามารถนำมาใช้ในการประมวลผลงานที่ต้องการได้
อีกมุมมองหนึ่งคือการพิจารณาขีดความสามารถของภาษาระดับสูง
ทุกโปรแกรมที่ใช้ภาษาระดับสูงจะต้องได้รับการแปลให้กลายเป็นคำสั่งภาษาเครื่อง
เพื่อที่จะได้นำไปประมวลผล
ที่อยู่อ้างอิงในคำสั่งเครื่อง
วิธีที่นิยมใช้ในการอธิบายสถาปัตยกรรมคอมพิวเตอร์คือ
การอธิบายจำนวนของที่อยู่อ้างอิง ในคำสั่งเครื่องแต่ละคำสั่ง
วิธีการนี้ได้รับความนิยมน้อยลงเมื่อมีการออกแบบซีพียูมีความสลับซับซ้อนมากขึ้น
คำสั่งแต่ละคำสั่ง
มีความจำเป็นจะต้องอ้างอิงที่อยู่เป็นจำนวนเท่าใด
คำสั่งเกี่ยวกับคณิตศาสตร์และตรรกะ
มักจะต้องการอ้างอิงที่อยู่ของตัวถูกดำเนินการมากกว่าคำสั่งชนิดอื่น
โดยทั่วไปคำสั่งในกลุ่มนี้จะเป็นคำสั่งประเภท อันนารี หรือ ไบนารี
ผลลัพธ์ที่ได้จากการคำนวณจะต้องถูกนำไปเก็บไว้ในหน่วยความจำ
จึงอาจจะต้องอ้างอิงถึงที่อยู่แห่งที่สามในแต่ละคำสั่งนั้น
ด้วยเหตุผลดังกล่าว
ทำให้น่าเชื่อว่าคำสั่งแต่ละคำสั่งจะต้องการอ้างอิงที่อยู่สี่แห่งด้วยกัน
ในทางปฏิบัติแทบจะไม่มีคอมพิวเตอร์เครื่องใดที่มีการอ้างอิงอยู่มากถึงสี่แห่ง
คำสั่งส่วนใหญ่จะอ้างอิงที่อยู่จำนวนระหว่างหนึ่งถึงสามที่อยู่ต่อคำสั่ง
และนำที่อยู่ของคำสั่งต่อไปใส่ไว้ในรีจิสเตอร์แยกต่างหาก
8.3 ชนิดของตัวถูกดำเนินการ
คำสั่งเครื่องทำงานกับข้อมูลซึ่งสามารถแบ่งออกตามชนิดหรือประเภทได้ดังนี้
1. ตำเหน่งที่อยู่
2. ตัวเลข
3. ตัวอักษร
4. ข้อมูลภาพ
อันที่จริงตำแหน่งที่อยู่ก็เป็นข้อมูลชนิดหนึ่งในหลายกรณีมีการคำนวณเกิดขึ้นกับตัวถูกกระทำที่ถูกอ้างอิงในคำสั่งเครื่อง
เพื่อกำหนดตำแหน่งที่อยู่ในหน่วยความจำหลัก หรือในหน่วยความจำเสมือน
ในกรณีเช่นนี้ตำแหน่งที่อยู่จะถูกคำนวณในลักษณะเดียวกันกับเลขแบบไม่มีเครื่องหมาย
ข้อมูลตัวเลข
ภาษาเครื่องทุกชนิดจะมีข้อมูลชนิดตัวเลขไว้ใช้งาน
แม้กระทั่งงานที่ไม่เกี่ยวข้องกับตัวเลขก็ยังมีความจำเป็นจะต้องใช้ตัวเลขมาช่วยในการนับ
บอกความกว้างหรือขนาดของข้อมูล และอื่นๆ
ความแตกต่างที่สำคัญระหว่างตัวเลขที่เก็บอยู่ในคอมพิวเตอร์ คือ ตัวเลขคอมพิวเตอร์มีขนาดที่จำกัดเนื่องจากเหตุผลสองประการ
ประการแรก
ตัวเลขที่เก็บอยู่ในคอมพิวเตอร์นั้นถูกจำกัดขนาดด้วยรูปแบบที่ใช้อยู่ในเครื่องนั้น
ประการที่สอง
ในกรณีของเลขจำนวนจริงก็ถูกจำกัดขนาดด้วยระดับความเที่ยงตรงที่ต้องการนักพัฒนาโปรแกรมจึงต้องทำความเข้าใจในผลที่เกิดขึ้นจากการปัดเศษ
โอเวอร์โฟลว์ และการ อันเดอร์โฟลว์
ข้อมูลตัวอักษร
รูปแบบข้อมูลที่ใช้งานทั่วไปคือ ตัวอักษร
หรือข้อความ ข้อมูลที่เป็นข้อความนั้น เป็นรูปแบบ ที่สะดวกสบายต่อคน
แต่ในเวลาเดียวกันก็เป็นรูปแบบที่ไม่สามารถเก็บไว้ในคอมพิวเตอร์ หรือนำไปประดิษฐ์รหัสสำหรับการเก็บข้อมูลตัวอักษรไว้ในคอมพิวเตอร์
รหัสแบบแรกที่ได้รับการออกแบบมาใช้งานคือ รหัสมอส
ในปัจจุบันโค้ดรหัสที่ถูกนำมาใช้อย่างแพร่หลายเรียกว่ารหัสแอสกี
ได้รับความนิยมนำไปใช้งานทั่วโลก
ตัวอักษรแต่ละตัวในรหัสนี้ถูกแทนด้วยเลขฐานสองจำนวน 7 บิต
ทำให้สามารถกำหนดสัญลักษณ์ได้ 128 แบบ
ซึ่งเป็นจำนวนที่มากเกินพอสำหรับตัวอักษรที่สามารถพิมพ์ออกมาทางเครื่องพิมพ์ได้
รหัสส่วนหนึ่งจึงถูกนำไปใช้เป็นรหัสควบคุมในขณะที่รหัสส่วนที่เหลือถูกนำไปใช้ในการสื่อสารข้อมูล
ข้อมูลตรรกะ
โดยปกติแต่ละเวิร์ด
หรือแต่ละหน่วยสามารถอ้างอิงได้
จะถือเสมือนหนึ่งว่าเป็นข้อมูลหน่วยเดียวแต่ในบางครั้งก็มีความจำเป็นจะต้องพิจารณาข้อมูลในแต่ละหน่วยนั้นครั้งละ
1 บิต ซึ้งจะมีค่าเป็น 0 หรือ 1 เมื่อข้อมูลถูกมองในลักษณะนี้
เรียกว่าเป็นข้อมูลแบบตรรกะ
การมองข้อมูลครั้งละ 1 บิต มีประโยชน์สองประการ
ประการแรก คือ
บางครั้งก็มีความจำเป็นจะต้องเก็บข้อมูลอาร์เรย์แบบบูลลีน
หรือข้อมูลที่เป็นเลขฐานสองโดยตรง ซึ่งข้อมูลแต่ละตัวจะกินเนื้อที่เพียง 1 บิต
เท่านั้น การเก็บข้อมูลแบบตรรกะจึงถูกนำมาใช้งานประเภทนี้ได้อย่างมีประสิทธิภาพ
ประการที่สอง คือ ในบางครั้งก็มีความจำเป็นจะต้องจัดการกับข้อมูลธรรมดาครั้งละ 1
บิต
8.4 การบ่งตำแหน่งที่อยู่
เมื่อซีพียูจะทำงานตามคำสั่งที่เขียนไว้ในหน่วยความจำจะต้องนำคำสั่งจากหน่วยความจำถ่ายลงสู่ซีพียูแล้วจึงประมวลผลตามวัฏจักร
ดังได้กล่าวมาแล้ว แต่ละคำสั่งจะมี ออปโค้ด เป็นไบต์แรก
แล้วตามด้วยข้อมูลหรือตำแหน่งข้อมูล ในไบต์ที่สองและสาม
เมื่อซีพียูแปลรหัสออปโค้ดแล้วจะทราบว่า จะต้องไปนำข้อมูลจากที่ใดมาปฏิบัติต่อ
เพื่อให้คำสั่งนั้นแล้วเสร็จวิธีต่างๆที่ซีพียูไปนำข้อมูลมาจากหน่วยความจำดังกล่าวนี้เรียกว่า
การบ่งตำแหน่งที่อยู่ หรือแอดเดรสซิงโหมด
การบ่งตำแหน่งทันที
เป็นรูปแบบของการบ่งตำแหน่งที่ง่ายที่สุด
ตัวถูกกระทำจะปรากฏอยู่ ในคำสั่งนั้น
หรือค่าของตัวถูกกระทำจะเขียนตามหลังคำสั่งตำแหน่งที่ติดต่อกัน ซึ่งหมายความว่า
เราสามารถที่จะดึงตัวถูกกระทำออกจากหน่วยความจำได้
ในเวลาเดียวกันกับที่ดึงคำสั่งขึ้นมาทำงาน
ดังนั้นจึงประหยัดวงรอบของการทำงานอ้างอิงหน่วยความจำไปได้หนึ่งรอบ
การบ่งตำแหน่งโดยตรง
รูปแบบที่จัดว่าง่ายอีกวิธีหนึ่งคือ
การบ่งตำแหน่งโดยตรง
ซึ่งเขตข้อมูลตำแหน่งที่อยู่จะบรรจุตำแหน่งจริงของตัวถูกกระทำเอาไว้ดังนี้
EA=A
วิธีการนี้ได้รับความนิยมในการใช้งานกับคอมพิวเตอร์ รุ่นแรกๆ
แต่ไม่เป็นที่นิยมในปัจจุบัน การประมวลผลจะต้องใช้วงรอบการอ้างอิงหน่วยความจำเพิ่มอีกหนึ่งรอบโดยไม่ต้องคำนวณเพิ่มเติม
ข้อด้อยประการสำคัญคือ ขอบเขตที่จำกัดในการอ้างอิงข้อมูลในหน่วยความจำ
การบ่งตำแหน่งทางอ้อม
เนื่องจากวิธีอ้างอิงโดยตรงนั้น
ความยาวของเขตข้อมูลตำแหน่งที่อยู่มักจะมีขนาดสั้นกว่าความยาวของหนึ่งเวิร์ด
จึงทำให้ขอบเขตในการอ้างอิงข้อมูลลดลง
การแก้ไขปัญหานี้ทำได้โดยการใช้ขอบเขตข้อมูลตำแหน่งที่อยู่ในการอ้างอิงทางอ้อม
อ้างอิง
http://neung.kaengkhoi.ac.th/mdata/rsdata4.html (สืบค้นวันที่ 21 ตุลาคม 2558)
ไม่มีความคิดเห็น:
แสดงความคิดเห็น